

Deploy OpenClaw on High-Performance VPS
Run your self-hosted AI assistant on NVMe-powered VPS infrastructure with full root control.

Recommended VPS for OpenClaw
For optimal performance, we recommend our latest generation VPS with NVMe storage and DDR5 memory.
VPS STANDARD
2 vCores
4 GB DDR5 RAM
50 GB NVMe SSD
100 Mbit/s
Suitable for testing and light workloads.
VPS PROFESSIONAL
4 vCores
8 GB DDR5 RAM
100 GB NVMe SSD
100 Mbit/s
Recommended for production deployments and heavier automation.
OpenClaw can also run on lower-cost VPS with SATA SSD or HDD storage if performance requirements are minimal.
PRICING
Transparent Pricing
OpenClaw is open-source software. Your total cost consists of what you actually use. Nothing hidden, nothing per-seat.
Your VPS Plan
Predictable monthly infrastructure cost from Server4You. No per-seat fees, no surprises.
AI Provider API
Usage billed directly by OpenAI, Anthropic, Google or run Ollama locally at zero model cost.
Everything Else
$0. No per-message fees. No per-user fees. No integration charges.
OVERVIEW
What is OpenClaw?
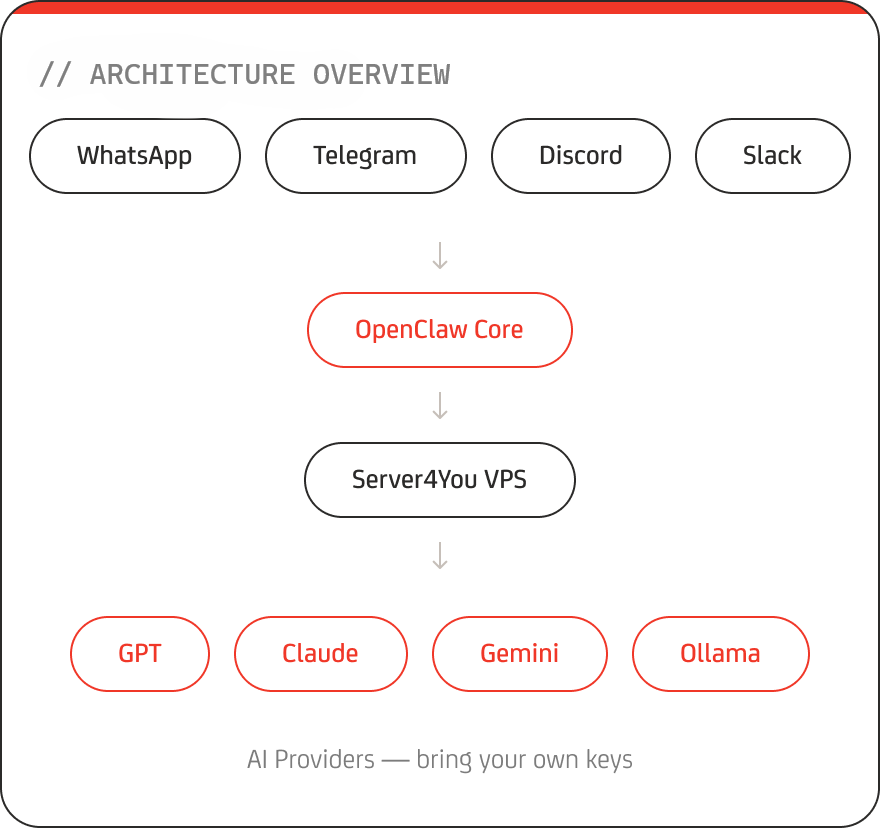
OpenClaw is a self-hosted, open-source AI assistant platform that connects large language models (LLMs) to messaging platforms such as WhatsApp, Telegram, Discord, Slack, iMessage, and more.
Unlike cloud-based AI services, OpenClaw runs entirely on your own server. You stay in control of your data, integrations, and AI provider selection.
- −Multi-platform messaging support over 50+ integrations
- −Persistent AI memory across sessions
- −Automation & workflow execution
- −Web-based management dashboard
- −Support for GPT, Claude, Gemini, and local models
DEPLOYMENT
Deploy OpenClaw in 4 Simple Steps

Pick Your VPS
Choose the plan that fits your OpenClaw needs, from trial to full production. We offer options for every use case.

Order & Pay
Log in or create an account, select your data center, and complete your payment.

Deploy OpenClaw
Once your VPS is assigned, choose Debian 13 or Ubuntu 24.04 with OpenClaw pre-installed and start the OS installation.

Start Automating
Access your VPS via SSH or web interface, add your AI API keys, connect messaging apps, and launch your assistant.
CONTROL
Your AI.
Your Server.
Your Rules.
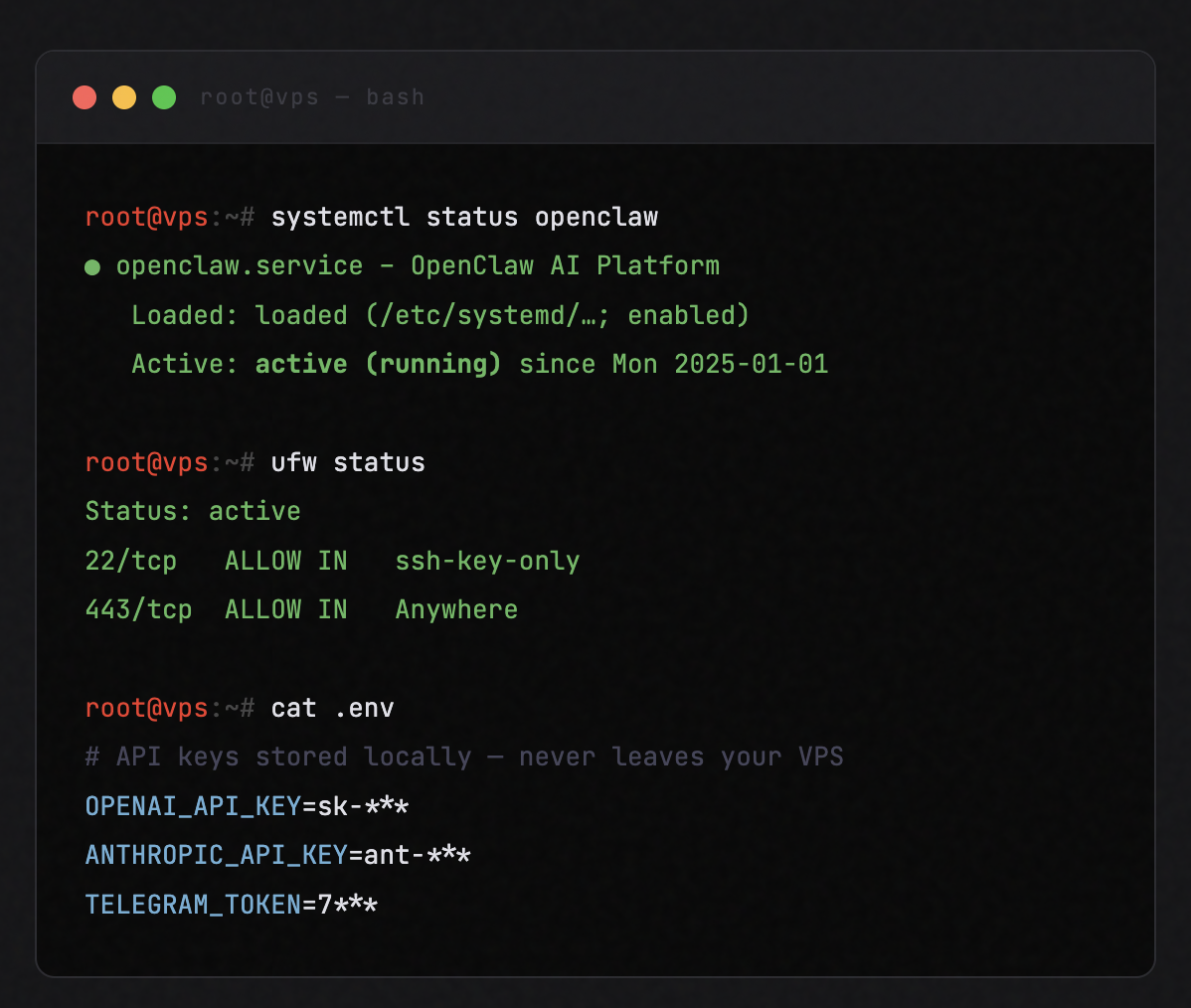
- −Isolated VPS environment - no shared compute, no noisy neighbours.
- −Custom firewall configuration down to the individual port level.
- −SSH access control with key-based authentication.
- −API keys stored exclusively on your server - never in our systems.
- −No vendor lock-in. Migrate or export your data at any time.
USE CASES
What Can You Build With OpenClaw?
AI Chat Assistant
Deploy a persistent assistant connected to messaging platforms. Always-on, context-aware, fully yours.
Workflow Automation
Automate tasks, execute scripts, manage files, and trigger APIs - all orchestrated through OpenClaw.
Business Integration
Connect OpenClaw to your databases, tools, and services. Custom integrations without SaaS overhead.
Personal AI Infrastructure
Run your own AI environment. Choose your models, own your data, set your rules - no vendor lock-in.
INFRASTRUCTURE
Infrastructure Built for AI Workloads
NVMe SSD Storage
Ultra-fast disk I/O for rapid model loading, log processing, and file operations.
DDR5 Memory
Modern DDR5 architecture delivers the bandwidth AI workloads demand to stay responsive.
High-Performance vCores
Optimized for reliable and consistent performance under sustained load.
100 Mbit Connectivity
More than sufficient for API calls, messaging integrations, and automation tasks.
EU & US Data Centers
Strasbourg (FR) and St. Louis (USA) - optimised for low latency wherever you operate.
Full Root Access
Complete server control. Configure, customise, and secure your environment exactly as needed.
OpenClaw runs continuously - your infrastructure should too.
WHY IT MATTERS
Why NVMe & DDR5 Matter for AI Agents
AI automation workloads involve frequent API calls, background processes, disk operations, and sustained memory usage. Fast storage and modern memory directly reduce latency and improve overall responsiveness.
Faster read/write speeds reduce response lag during model operations
Improved multi-tasking across concurrent AI agents and automations
Reduced processing delays on complex multi-step workflows
Stable, predictable performance under continuous always-on workloads
Indicative performance comparison